Advanced Celery for Django: fixing unreliable background tasks

.webp)
Operating Python's Celery reliably can be challenging, much like any distributed system. It is a powerful solution for asynchronous processing in Python web backends, especially Django projects. However, Celery requires diligent management and monitoring. After a decade of building Python products and consulting with teams facing these exact challenges, we at Vinta have extensively utilized Celery across dozens of client projects, which has led us to encounter almost every failure scenario imaginable.
There are other options for managing task queues, but we believe you won't find another library that matches Celery's extensive feature set. Therefore, it makes more sense to adapt to its limitations and challenges.
If you want to build a resilient asynchronous system, learning how to handle Celery's shortcomings is essential — especially in advance. Our goal in this blog post is to help you effectively manage failed and lost tasks, which can occur for a multitude of reasons.
You can also check out the talk at DjangoCon, on which this blog post is based.
Common Pitfalls When Managing Tasks in Celery
As a CTO or senior engineer, you've likely learned that distributed systems introduce failure modes that don't exist in monolithic applications. Celery, while powerful, amplifies these challenges in ways that can catch even experienced teams off guard.
The reality is straightforward: every connection point in your architecture becomes a potential point of failure. Your web servers, message brokers, workers, and databases must all coordinate perfectly for tasks to execute reliably. When any component fails or becomes temporarily unavailable, tasks can be lost, duplicated, or executed in unexpected states.
What makes this particularly challenging for technical leadership is the unpredictable nature of these failures. Unlike application bugs that can be reproduced and fixed, distributed system failures often manifest as intermittent issues that are difficult to diagnose and can significantly impact the user experience.
It is essential to recognize that failed and lost tasks can disrupt user flows and negatively impact the overall user experience. For example, consider the common scenario where a user signs up for an application but does not receive the email with the account activation link. This situation can lead to frustration and confusion, as the user is unable to complete the signup process.
To mitigate such issues, it is crucial to implement robust task management practices within your Celery setup. By ensuring task reliability and actively monitoring task execution, you can maintain smooth user interactions and enhance the overall functionality of your application.

Handling Task Loss Between Web Process and Broker
Task never queued due to broken connection
One significant concern in Celery is the possibility of tasks being lost due to connection failures. A task can fail to queue if there is a broken connection between the web process and the message broker. Suppose you attempt to queue a task using my_task.delay(x=2, y=3) while the broker is down or unreachable, you may encounter an OperationalError.
Fortunately, Celery has built-in mechanisms to handle such scenarios. By default, it will automatically retry task queuing up to three times, with a wait time of 0.2 seconds between each attempt. This feature helps mitigate the impact of temporary connection issues.
However, it is essential to note that even if the connection to the broker is stable, the task commit on the broker side can still fail. To enhance reliability, you can configure your RabbitMQ broker with the broker_transport_options Celery setting:
While this setting may introduce a slight delay in task processing, it ensures that once the task queuing is complete, the task is confirmed to be on the broker side. This is an important setting that developers should consider adjusting in their Celery configuration when using RabbitMQ.
Large task payloads can bring down broker
Another common pitfall involves the handling of large task payloads. Passing substantial data structures, such as large Python dictionaries, as task arguments can overwhelm the broker, bringing it down or at least causing performance issues.
For instance, at Vinta, we encountered a situation where our RabbitMQ data directories ballooned to 100 gigabytes due to the transmission of extensive XML data as task parameters.
It is advisable to pass data references rather than data values directly to avoid such issues. For example, you can utilize a blob storage service like Amazon S3 to store the data and send URLs as parameters to the tasks.
This approach allows the tasks to download the necessary data when needed, significantly reducing the load on the broker. Alternatively, consider using a database to store the data and pass relevant identifiers as arguments if you are dealing with relational data.
Losing tasks inside broker
Properly configuring brokers is critical to avoiding task loss. For RabbitMQ, ensure your server or cloud provider is configured to have durable queues and persistent messages.
If you're using Redis, ensure proper maxmemory policy. Do not use the policies allkeys-lru, allkeys-lfu, allkeys-random, because these will cause old or random tasks to be dropped when new ones are queued. Instead, it's best to have errors when queuing new tasks when the broker is full. While errors are never desirable, at least that kind of error is not random and difficult to debug.
It's also advisable to separate Redis instances depending on the usage: one instance for application cache, separate from an instance to act as Celery broker, and another as Celery's result backend. We've seen too many cases where a single Redis instance failure took down both the application cache and the task queue, creating a cascade failure that was particularly painful to recover from.
Mismatches between task state and business logic
Even in the most common usage, serious reliability issues can happen with Celery due to its distributed nature. In a typical sign-up flow, applications utilize Celery to send an activation email after the user successfully registers. Below is an example implementation using Django:
In this implementation, we use the transaction after the form validation and user creation .on_commit method to queue the task of sending the activation email. This ensures the user is committed to the DB before the task is queued.
However, this code still has an issue due to the nature of distributed systems. A mismatch between the task state and the underlying business logic can happen. While the database has successfully committed the change and the user has been created, a failure in the task queueing can result in the activation email task being lost.
Note that the DB has committed to the change: user sign-up is done from a business logic perspective. But, the activation email task is lost if the broker is down or the connection fails. The mitigations we discussed are not 100% guaranteed, as the broker might simply be down, and while the DB states all is fine with the user sign-up, the user won't ever be able to finish the sign-up because they won't receive the activation email.
In many applications, users are often left manually to request the activation email by clicking a "resend" button. While this is a common workaround, exploring solutions that provide automatic recovery mechanisms is essential.
Using the database as the source of truth for recovering tasks
One practical approach to recovering lost tasks is to use the database as the source of truth for task management. Sourcing tasks from the database ensures that tasks are queued even if the broker is temporarily unavailable. To implement this solution, periodic polling is necessary to check the database for any tasks that need to be executed.
For example, suppose a user is waiting for an account activation email. In that case, a periodic task can be set up to check the database for users who have not yet received their activation email. The system can queue the necessary tasks on the broker if such users are identified.
This proactive approach minimizes the need for manual intervention. Instead of relying on users to resend emails, you can implement periodic tasks with Celery Beat that automatically check the database and queue the appropriate tasks. This ensures that even in the event of a task infrastructure failure, users receive the necessary communications without unnecessary delays.
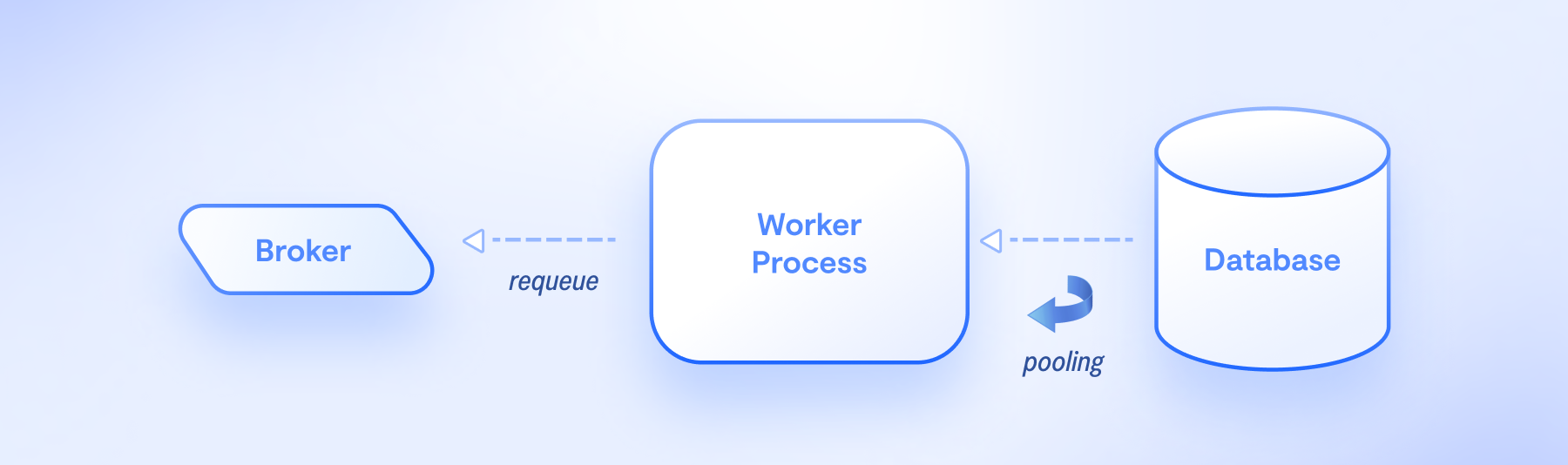
Here's an example implementation a periodic task that ensures the delivery of activation emails:
In this example, we define a task called task_ensure_activation_emails that iterates over users who have not yet had their activation email sent (is_activation_email_sent=False). For each of these users, we queue the task_send_activation_email task, passing the user's primary key as an argument.
By keeping the task_send_activation_email in the sign-up view, we maintain the fast behavior of sending the email immediately if everything is working correctly. However, we also have a consolidation mechanism to ensure the email is eventually sent if anything breaks during the sign-up process.
The task_ensure_activation_emails can be scheduled to run frequently, such as every five minutes, using Celery Beat. This way, even if the task fails to be queued during the sign-up process, the periodic task will eventually queue the task_send_activation_email for any users who have not yet received their activation email. Note that it's important for task_send_activation_email to set is_activation_email_sent to True after the email is successfully sent.
This approach combines the benefits of immediate email delivery during sign-up with a robust recovery mechanism in case of failures, ensuring that users consistently receive their activation emails.
Limitations of Celery for Complex Workflows
While Celery is well-suited for most asynchronous tasks use cases, it may not be optimal for building complex workflows or data-heavy pipelines. The approach sourcing tasks from the DB approach we just described might not be feasible for complex workflows. Imagine a scenario where you want to process numerous orders in parallel, such as millions of orders, and then notify a logistics system only after all orders have been processed.
Orchestrating complex and long-running workflows or data-heavy pipelines can be challenging with Celery and a database. While Celery provides constructs like Canvasworkflows, we at Vinta do not recommend using them due to various task loss issues and difficult exception handling. The number of GitHub issues in Celery's repository related to Canvas only keeps growing, and we've helped multiple clients migrate away from Canvas-based implementations after experiencing these issues in production.
Alternatives for Complex Workflows and Data Pipelines
For workflow-focused problems, dedicated workflow management tools are better. These tools offer better monitoring, operability, error handling, and the ability to run tasks anywhere, such as in pods, containers, or serverless environments. The downside is that integrating these tools with Django may not be as straightforward as Celery, which is why we often work with clients to evaluate the trade-offs based on their specific use cases.
Some recommended tools for complex workflows include:
Handling Task Loss Between Broker and Worker
Ensuring DB transactions are committed before queueing tasks
Earlier, we discussed using transaction.on_commit to ensure the user is committed to the DB before queuing the task. Let's dive deeper into that. This is particularly important when using ATOMIC_REQUESTS=True in Django, which wraps the entire view in a transaction. Let's imagine we aren't using transaction.on_commit, the code would look like this:
The trouble here is that right after the task_send_activation_email.delay call, the worker can execute the task while the view hasn't finished processing the request yet. The task will cause an exception, namely DoesNotExist(User matching query does not exist), because the user wasn't created yet, as the view didn't finish, and the transaction wasn't committed. Recall that the whole view is inside a transaction due to ATOMIC_REQUESTS=True, but the worker is not on that same transaction, as it runs in a separate Python process. The solution is to use transaction.on_commit to queue the task only after the transaction commits:
Handling worker failures and task acknowledgments
Workers can shut down unexpectedly for various reasons, such as deployments, infrastructure power outages, out-of-memory errors, etc. Consequently, you must have a strategy for safely removing tasks from the broker queue only after you're sure workers have processed them.
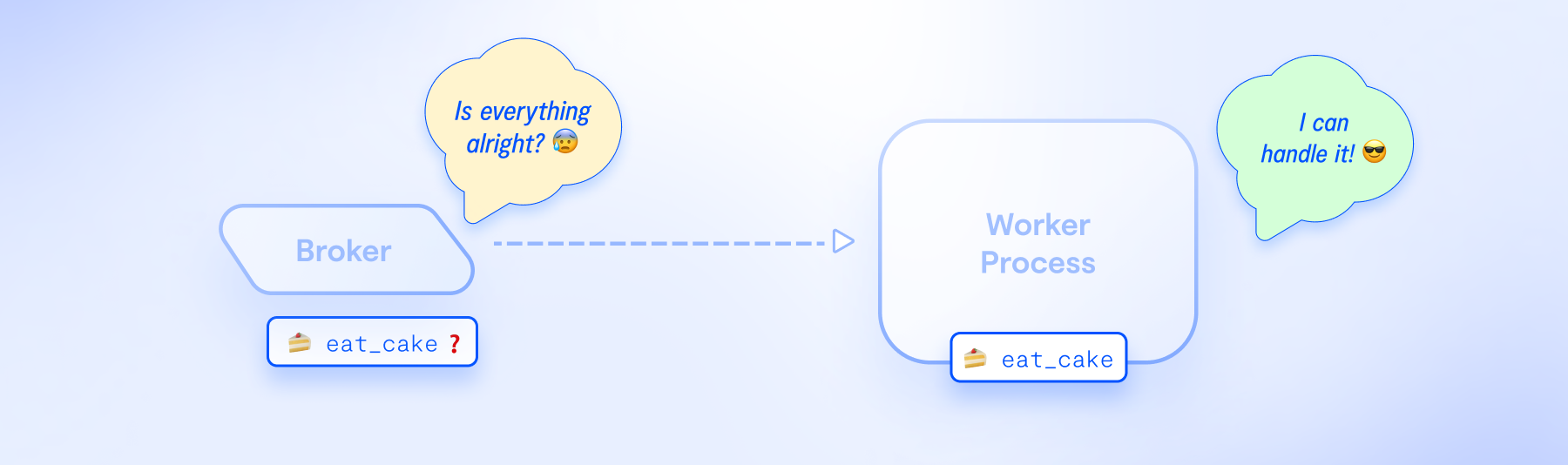
For example, consider a task called eat_cake. By default, when the broker sends this task to a worker, it is removed from the broker's queue. However, if the worker shuts down before completing the task, it will be lost, as it's already out of the broker. This situation highlights the need for careful management of task acknowledgments.
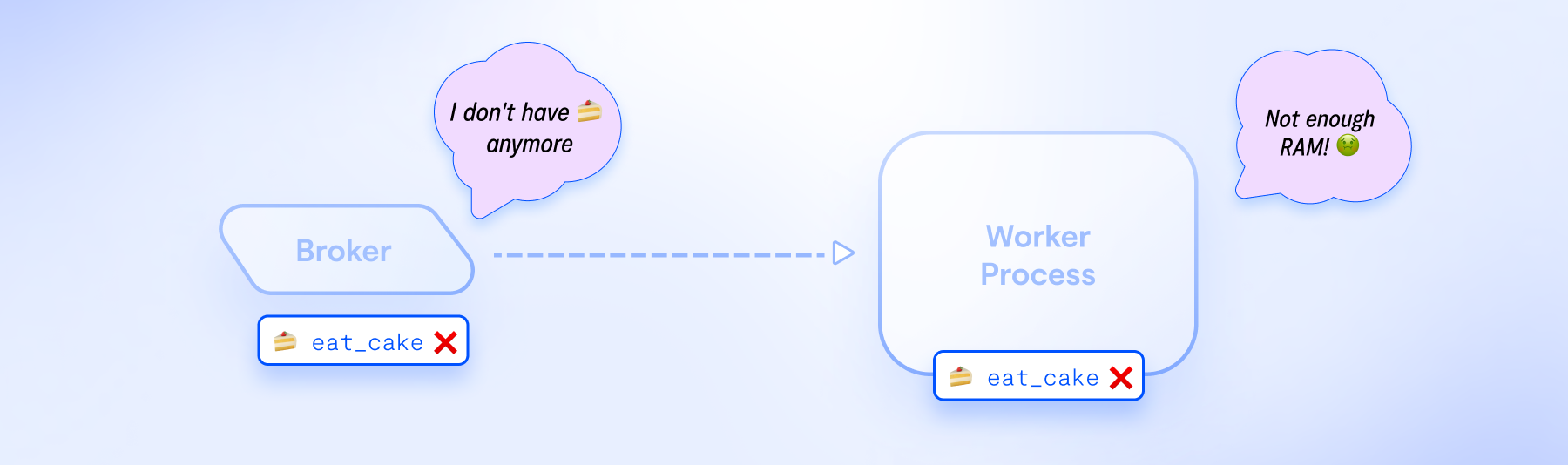
Understanding task acknowledgment behavior
Task acknowledgment means the worker tells the broker: "I'm good with this task; remove it from your queue." By default, Celery drops tasks from the broker immediately after the worker acknowledges them, which is controlled by the task_acks_late setting. This default behavior (task_acks_late=False) can lead to task loss if the worker shuts down before completing the task.
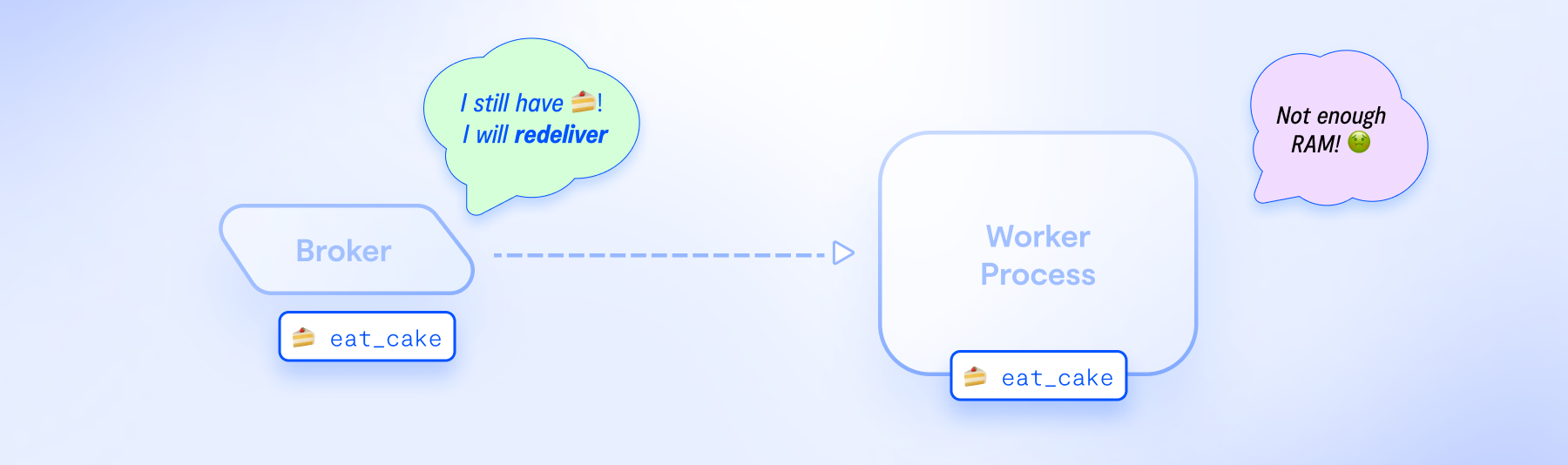
To enhance reliability, it is advisable to configure Celery only to drop tasks from the broker after the worker successfully executes them. This can be accomplished by setting task_acks_late=True. With this configuration, if the worker shuts down during task execution, the broker will redeliver the task, ensuring it is not lost.
When Celery drops tasks intentionally
Additionally, it is crucial to understand that Celery intentionally drops tasks on worker failure thanks to the setting task_reject_on_worker_lost=False. This can be surprising for developers because it seems contradictory with task_acks_late=True.
While task_acks_late=True will cause redeliveries when workers suddenly shut down, such as in a deployment or power outage, task_reject_on_worker_lost=False means that Celery will acknowledge tasks that cause segmentation faults, out-of-memory errors, or receive a SIGKILL signal. If a task runs and its worker process receives a SIGKILL due to memory issues, it will be automatically dropped and not redelivered. The parent-worker process detects when worker processes are killed, dropping tasks that cause this. That behavior is the default to prevent a redelivery loop of a "poison pill" task that causes workers to malfunction.
To ensure that tasks are redelivered after a worker failure, you can set the Celery to task_reject_on_worker_lost=True. Use this with caution, as you may get to even more lost tasks if your workers keep crashing due to the misbehaving task. You may want to have task_reject_on_worker_lost=True when you're confident task redeliveries will likely succeed, and the worker crashes are really transient, such as in rare out-of-memory situations.
Ensuring idempotency and safety in task execution
The downside of automatic task redelivery in Celery is that you, as a programmer, must ensure your task code is safely retriable and idempotent. Idempotency means executing the same task multiple times with the same arguments should not lead to unintended side effects. This is crucial for maintaining data integrity and ensuring that tasks can be re-executed without issues.
To achieve idempotency, you should utilize ORM methods such as get_or_create or update_or_create. These methods help prevent unnecessary work and side effects by ensuring that the task performs only the intended operations without duplicating data. If you're dealing with API integrations or other side effects, you must use idempotent operations in your task code.
In addition to idempotency, you should ensure atomicity in your task operations. Wrapping your task code in transaction.atomic can help manage database changes effectively. If a task is interrupted — whether due to a deployment or another issue — any changes made within the transaction will automatically roll back. This guarantees that the database remains in a consistent state, and the broker can redeliver the task for re-execution safely.
However, it is vital to be aware of side effects that cannot be rolled back, such as sending emails. In such cases, you can implement a strategy to couple these irreversible actions with the state of the database. For example, you can track whether an email has been sent in a database table and only send it if the database tells you it wasn't already.
To further enhance the reliability of task execution, it is advisable to keep tasks short and fast. This minimizes the risk of timeouts and makes it easier for the broker to manage task redelivery. Shorter tasks are also less likely to suffer from interruptions during execution, making them less prone to failures after redeliveries.
Understanding task redelivery mechanisms
So, how does task redelivery work in Celery? In the case of RabbitMQ, this process is largely automatic. Suppose you maintain a TCP connection with heartbeats between the broker and the worker. In that case, RabbitMQ will recognize when the worker has died and automatically redeliver any tasks assigned to that worker.
The mechanism is slightly different for other brokers, such as SQS and Redis. These brokers use a feature called visibility timeout. If a task is not acknowledged within a specified timeframe, it will be automatically redelivered.
The default visibility timeout is 30 minutes for SQS and one hour for Redis. You can configure this timeout using the broker_transport_options Celery setting, as shown below:
Understanding visibility timeout and task redelivery
One critical shortcoming of brokers with visibility timeout, such as SQS and Redis, is that once the visibility timeout elapses, the task is automatically redelivered, even if the worker is still processing it. This means the task is duplicated, which can lead to severe issues like race conditions, resource contention, or even deadlocks.
This presents a challenge: if a task takes longer than the visibility timeout to complete, it will be redelivered, resulting in duplicated work. On the other hand, increasing the visibility timeout to accommodate longer tasks can delay the redelivery of tasks in the event of a worker failure.
This creates a trade-off between fast redelivery and support for long-running tasks. Consequently, relying solely on visibility timeout may not be the best solution for all scenarios.
If you cannot optimize or simplify long-running tasks, consider using RabbitMQ as your broker, which does not require a visibility timeout. Alternatively, you might choose to avoid using Celery for workflows that involve long-running tasks altogether.
Another option is to set task_acks_late=False, which is the default behavior. While this setting avoids the visibility timeout, it also means that tasks may be lost if a worker fails, as discussed before.
Handling task exceptions
It is also essential to handle exceptions properly when handling your tasks. While setting task_acks_late=True helps manage unexpected shutdowns, it does not address the situation where a task raises an exception. For example, if a task attempts to retrieve a cake object with cake.objects.get(name="Fantasy Cake") and raise a cake.DoesNotExist exception, the task will be acknowledged as complete, resulting in its loss.
This is controlled by the setting task_acks_on_failure_or_timeout, which defaults to True. While you can change this setting, it is generally advisable to leave it as is and instead explicitly decide how to handle exceptions and retries.
Best practices for exception handling and retries
Ideally, you should handle all possible exceptions in your tasks with the same diligence you apply to managing 500s in Django Views. Consider using Celery's built-in retry functionality if your tasks depend on external APIs or are prone to intermittent errors.
Here’s an example of how to implement retries in a task:
In this example, the task will automatically retry up to five times with a default delay of 30 seconds between attempts if an EmailException is raised. This approach helps ensure that transient integration errors do not result in task failures.
Managing task changes with queued Celery tasks
When deploying changes to your application, it is crucial to consider the state of queued Celery tasks. If tasks are in the queue, modifying the task signature — such as changing the function parameters — can lead to issues.
After deployment, new worker processes may be unable to handle tasks queued with the previous parameters. For instance, if you change a task from task_eat_cake(cake_id) to task_eat_cake(cake_id, person_id), the new workers will struggle to process the old tasks queued with only cake_id. This can result in cryptic errors and task failures.
To avoid these complications, ensure all queues are empty before changing task signatures. This precaution will help prevent confusion and errors related to mismatched parameters. Alternatively, deploy the new task version alongside the old one if it's possible to keep the old one working correctly. Then, after you're sure there are no more queued tasks with the old signature, make another deployment, removing the old task.
Also, be cautious when upgrading Celery, as changes in the internal task payloads can cause issues. Similar to changing task signatures, these alterations can lead to cryptic errors that are difficult to diagnose.
Furthermore, ETA (Estimated Time of Arrival) tasks can pose a problem because they reside in the worker's memory while waiting to execute. This behavior can complicate matters, especially if the task signature or payload changes during deployment. Therefore, avoiding using ETA or countdown tasks that extend beyond a few seconds is generally advisable.
The same principle applies to retries, as retries are essentially ETA tasks behind the scenes.
Considerations for running Celery tasks during deployments
When deploying code updates, you must decide how to handle existing Celery workers. Specifically, consider whether you will send a SIGTERM (graceful termination, warm shutdown) or a SIGQUIT (forceful termination, cold shutdown) to the existing worker process before starting the new ones. While SIGTERM will wait for running tasks to finish, SIGQUIT will just try to re-queue the unacknowledged tasks (running tasks when task_acks_late=True) and shut down immediately. This re-queue mechanism is not guaranteed, as race conditions can happen (if you're curious, look for issues that mention "unacked" in Celery and Kombu repositories).
There's a better solution in a new type of shutdown introduced at Celery 5.5 called soft shutdown. It's a time-limited warm shutdown. We highly recommend using it if you can upgrade your Celery. Controlled by the new setting worker_soft_shutdown_timeout, you can set the number of seconds the worker will wait before the cold shutdown is initiated, and the worker is terminated. This is the best of both worlds, as it allows for some time for the worker to finish short tasks and re-queue long-running tasks. You'll also want to enable the setting worker_enable_soft_shutdown_on_idle to prevent losing ETA and retry tasks.
Beware that if your deployment process sends SIGKILL to worker processes before any Celery shutdown mechanism is done, the task_reject_on_worker_lost default behavior we discussed earlier comes into play. In this case, Celery will assume you want to interrupt the task, preventing it from being retried or redelivered. It's possible to send SIGKILL to the parent worker process before sending the same signal to the workers to keep redelivery working. However, this can be tricky to implement in a deployment script.
In any case, double-check the status of your old worker processes after deployment. Ensure they have been properly terminated and verify that task redelivery of running and prefetched tasks is functioning as expected. As discussed in the previous section, pay extra attention to ETA and retry tasks.
Handling Clogged Queues
Route Tasks Properly
To enhance task management, consider routing priority tasks to dedicated queues and workers. This approach allows priority tasks to be finished faster and circumvents clogged queues.
Timeout Slow Tasks
Implementing task time limits is also essential for managing poorly behaving requests and integrations that may take excessive time to complete. Setting timeouts and limits can help ensure that such tasks do not hinder the overall performance of your application.
Chances are you have HTTP requests inside your tasks that take a long time to fail but would succeed if you just retry. Without timeouts, tasks can be blocked indefinitely, and that halts workers and clogs queues. For any operation that deals with external systems, it's important to set a timeout and handle the exception in case it happens (perhaps with a retry).
It's also possible to set time_limit on tasks or use the global task_time_limit setting. Remember task_acks_on_failure_or_timeout defaults to True, therefore tasks that suffer a timeout won't be redelivered automatically.
Expire Tasks that Don't Make Sense Anymore
Consider setting an expiration for tasks that should not run after a specific date or time. For example, it can be frustrating for users to receive notifications about events that occurred in the past. To improve user experience, set up expireswhen delaying these types of tasks.
Monitoring and Alerts
Establishing robust monitoring, alerts, and observability for your Celery tasks is crucial. This is an area where we see many teams struggle, often because they underestimate the complexity of monitoring distributed task systems.
Utilize tools that provide insights into task performance and failures. Large monitoring players like Datadog and New Relic have built-in RabbitMQ, Redis, and Celery integrations, with good performance tracking and task tracing support. Similar free and open-source tools are also an option.
Setting up Correlation IDs to correlate Django requests with the Celery tasks they generate is a must-have for proper monitoring. You can use the django-guid library for that.
By implementing these monitoring strategies, you can proactively address issues and ensure that your Celery infrastructure operates smoothly. Setting up alerts for task failures and deep-diving into task traces to identify performance bottlenecks will help you maintain a reliable task management system.
Recommended Settings
Many of this article's suggestions relate to Celery's settings. Based on our experience across numerous production deployments, here is the full list of recommended Celery settings for Django projects, with extensive commentary for each setting.
Conclusion
By applying these principles and techniques, you can create Celery-powered applications that are resilient, scalable, and handle complex asynchronous tasks reliably. These lessons come from years of production experience across different industries and use cases.
Effective task management involves understanding underlying mechanisms, anticipating pitfalls, and implementing robust strategies. Celery reliability is just one piece of building robust Django applications at scale. From database optimization and caching strategies to API design and deployment practices, each component requires thoughtful architecture and proven patterns.
Working with teams who have navigated these challenges across the Django ecosystem can significantly accelerate your journey to production-ready applications that scale with your business needs.









